- September 14, 2022
- Posted by: Mahesh S
- Category: Engineering

The Problem
The most common problem faced by a data-centric application is Data consistency and the question that how and when the data got changed like how it is in the present state.
For example, in an E-Commerce application, it is common that a Product can get numerous updates to its data within a short span of time. Similarly, the Cart and Order statuses change frequently.
And in a Banking application, a huge number of transactions happen within seconds and the Account states change frequently.
So, it becomes more or less necessary that there should be a way to know who changed the data to its present state at a particular point of time.
This is where Event Sourcing comes into play.
The Solution
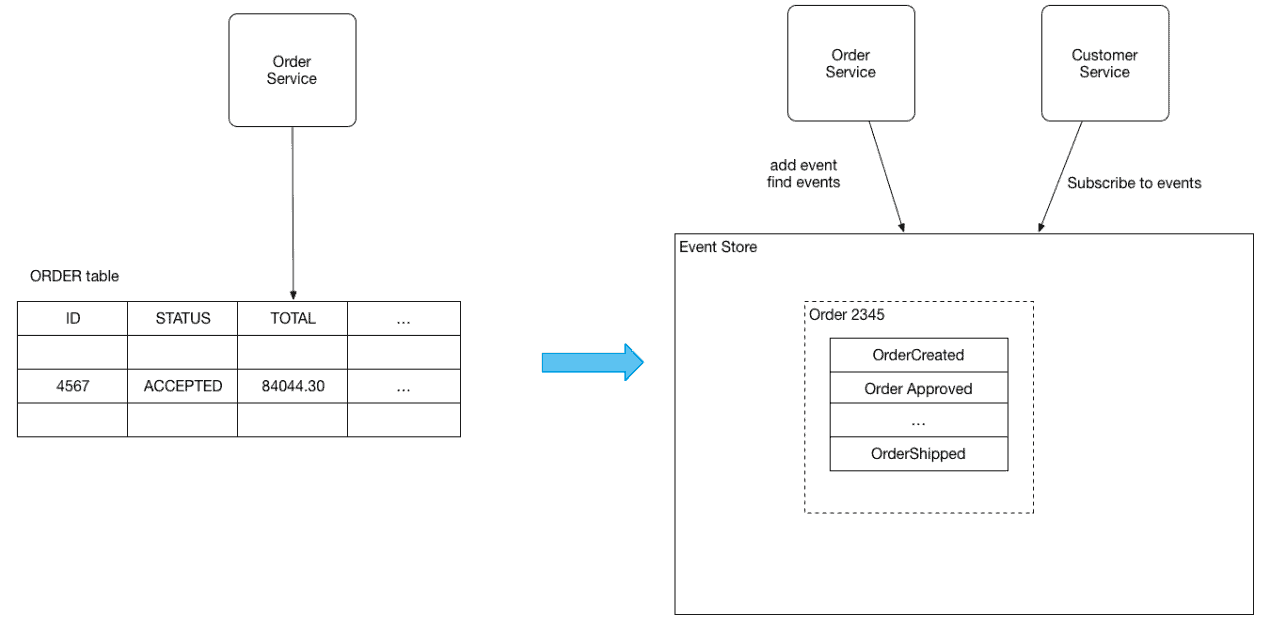
Event Sourcing logs the state of an entity such as an Order or a Customer as a sequence of state-changing events.
Whenever the state of an entity changes, a new event is appended to the list of events. Since saving an event is a single operation, it is atomic. The application reconstructs an entity’s present state by replaying the events.
Applications save events in an event store, which is a database of events. The store has an API for adding and fetching an entity’s events. The event store also acts as a message broker. It provides an API that enables services to subscribe to events. When a service saves an event in the event store, it is delivered to all interested subscribers.
Some entities, such as an Order, can have a large number of events. In order to optimize loading, applications periodically save a snapshot of an entity’s current state. To reconstruct the current state, the application finds the most recent snapshot and the events that have occurred since that snapshot. As a result, there are fewer events to replay.
How it works
Events are all saved in an event store. Each event that is logged in the event store is delivered by the event store to all interested subscribers. The event store is the backbone of an event-driven microservices architecture.
In this architecture, requests to update an entity (either an external HTTP request or an event published by another service) are handled by fetching the entity’s events from the event store, reconstructing the current state of the entity, updating the entity, and saving the new events.
Example
The End Result
As you can see, event sourcing addresses the challenge of implementing an event-driven architecture. Additional significant benefits of persisting events include the following:
- Easy temporal queries – Because event sourcing maintains the complete history of each business object, implementing temporal queries and reconstructing the historical state of an entity is straightforward.
- 100% accurate audit logging – Auditing functionality is often added as an afterthought, resulting in an inherent risk of incompleteness. With event sourcing, each state change corresponds to one or more events, providing 100% accurate audit logging.
When to use this pattern
Use this pattern in the following scenarios:
- Small or simple domains, systems that have little or no business logic, or nondomain systems that naturally work well with traditional CRUD data management mechanisms.
- When you want to capture intent, purpose, or reason in the data. For example, changes to a customer entity can be captured as a series of specific event types, such as Moved home, Closed account, or Deceased.
- When it’s vital to minimize or completely avoid the occurrence of conflicting updates to data.
- Systems where history, capabilities, audit trails to roll back and replay actions are not required.
- When you want to keep a history and audit log, record events that occur and be able to replay them to restore the state of a system, roll back changes. For example, when a task involves multiple steps you might need to execute actions to revert updates and then replay some steps to bring the data back into a consistent state.
- When using events is a natural feature of the operation of the application, and requires little additional development or implementation effort.
- When you need to decouple the process of inputting or updating data from the tasks required to apply these actions. This might be to improve UI performance, or to distribute events to other listeners that take action when the events occur. For example, integrating a payroll system with an expense submission website so that events raised by the event store in response to data updates made in the website are consumed by both the website and the payroll system.
- Systems where there’s only a very low occurrence of conflicting updates to the underlying data. For example, systems that predominantly add data rather than updating it.
- When you want the flexibility to be able to change the format of materialized models and entity data if requirements change, or—when used in conjunction with CQRS—you need to adapt a read model or the views that expose the data.
- When used in conjunction with CQRS, and eventual consistency is acceptable while a read model is updated, or the performance impact of rehydrating entities and data from an event stream is acceptable.
This pattern might not be useful in the following situations:
- Systems where real-time updates and consistency to the data views are required.