- January 6, 2023
- Posted by: Yadu Dev
- Category: Engineering
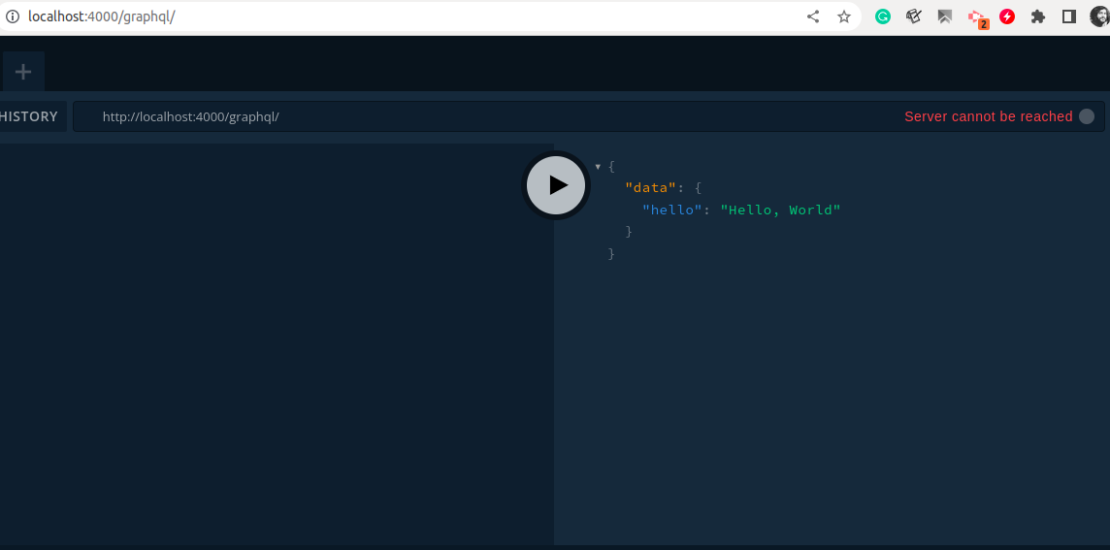
What is graphql?
GraphQL is a query language for APIs and a runtime for fulfilling those queries with existing data. With the help of GraphQL, you can provide a complete and understandable description of the data in your API, So the clients have the power to ask for exactly what they need, and nothing more. without any over-fetching or under-fetching, ensuring that apps using GraphQL are fast, stable, and scalable.
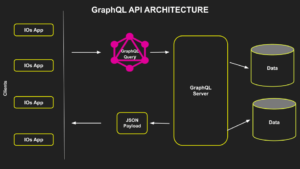
How Does GraphQL Work?
Let’s check how GraphQL actually works and how it has differed from other methods.
GraphQL allows you to define your own strongly typed schema using a GraphQL Schema Definition Language. You can think of this as a contract between the server and client, which means the server side exposes only what you define through your schema, and the client gets only what is offered by the schema. Having a schema also allows early detection and correction of issues during the development stages.
Object type is the most essential component of a GraphQL schema. It represents the kind of object you can fetch from your service and what fields it has. In the GraphQL schema language, a GraphQL object type might look like the following –
type Cat { name: String }
In a GraphQL API, a user can perform three types of operations: queries, subscriptions, and mutations.
queries: Used to fetch data from a server. Clients fetch data using GraphQL queries, equivalent to the ‘read’ operation in the CRUD pattern. With queries, clients can only bring data but not modify it.
type Query {
hello: String!
}mutation: To modify data (i.e., perform create, update, and delete operations), mutation types need to be used.
type Mutation {
createCat(name: String!): Cat!
}Subscriptions: are long-lived requests that fetch data in response to certain trigger events. This can help you to build real-time functionality into your applications by accessing notifications and data changes typically over a web socket.
type Subscription { commentAdded(repoFullName: String!): Comment }
Query, mutation, and subscription commands are dealt with by a resolver, a collection of functions that generates responses for a graphQL query. You can think of a resolver like a GraphQL query handler.
schema { query: Query mutation: Mutation subscription: Subscription }
Issues With REST APIs
- Querying Multiple Endpoints
- OverFetching
- UnderFetching and n+1 Request Problem
- Not super fast to cope up with changing client end requirements
- High Coupling between Backend Controllers and Frontend Views
What are the benefits of using GraphQL?
GraphQL provides the following benefits:
- Flexibility to Clients – With GraphQL, clients such as mobile can exactly query for information that they need, and the server will respond with only that data. I.E clients dictate what data the server needs to respond with as opposed to the server, thereby avoiding the overfetching problem with REST. Imagine how useful this is for mobile, especially when there is a slow network.With GraphQL, clients make a single API call to fetch the information they need. This reduces the integration overhead and improves network performance. No more client-side joins or error handling.
- Flexibility to API Developers – GraphQL saves the effort needed by API developers to build custom endpoints in orchestration layers or experience APIs for all possible query combinations since you can construct different page views on the client using the same endpoint and schema. Also, we can reuse this aggregation logic to support diverse clients that have varied querying needs instead of building separate BFFs per client. This simplifies the orchestration layer that one needs to maintain.
- Versioning – With GraphQL, it’s easier to know which fields in the API are being used by what clients and which ones are not. API developers can more confidently make changes to the existing APIs with this information. This means you don’t need to implement a new version when removing certain unused fields or adding new fields or types. The API can keep growing and clients need not worry as much about upgrading to the latest version. This is a stark difference from REST.
- Documentation & Schema – GraphQL uses a strongly typed schema against which queries are validated. Through GraphQL introspection, one can request the schema and know what queries are supported; this can then be used for automatic generation of documentation. Also, tools like GraphiQL can help you visually explore the graph of data and help one to author and submit a GraphQL query to the server. In REST API’s this documentation has to be explicitly created using Swagger or some other mechanism.You can also specify which fields are nullable in the schema. I.E if there is an error fetching certain fields, the other fields can still be returned in the response.
- Efficient data loading – GraphQL minimizes the amount of data transferred from the server, thus decreasing network usage. This is very important for mobile and low-powered devices, especially when connected to a bad network [1].
- Interoperability – As the clients can select the data they need, it’s easy to provide compatibility with different clients.
- Good for modernizing legacy systems – It’s easy to add GraphQL in front of legacy systems, so providing a more modern API without the need to change the legacy APIs.
- Good for microservices – GraphQL Federation facilitates the development and integration of microservices a lot. As an example, Netflix has been using this technique to integrate its large number of microservices.
- Fast development – Because of GraphQL flexibility, development changes are reduced, because the server can expose all possible data and the clients can get all required data within a single query, without major adjustments. Clients can also use GraphQL fragments, which are snippets of logic that can be shared in multiple operations.
What is REST good for?
Until now, I imagine that we share the same opinion that GraphQL is awesome, but that’s not entirely true. There are still some missing elements to make it perfect. If you aim to have one of the next points in your project, you should consider the usage of REST.
What is GraphQL good for?
Nowadays, almost every business aims to build mobile cross-platform applications because the customer interaction with the product increases significantly if they are able to access it via their phones. When you use a mobile app, you expect them to be responsive and with low latency.
By using GraphQL you will be able to achieve these goals in a really easy way. It helps the client to fetch the amount of data needed to render a specific view.
What makes GraphQL a better choice:
- Clients can specify exactly what data they need.
- Collecting data from multiple sources is easy.
- GraphQL uses a type system to describe data rather than endpoints.
GraphQL with Nodejs
Let’s create a new node project, here I am avoiding those steps to create a new node project because I hope you are familiar with them. While you create a new node project, it initializes with a package.json file. package.json is the configuration file for the Node.js app you’re building. It lists all dependencies and other configuration options (such as scripts) needed for the app.
So we can start with Creating a GraphQL server
After initializing the application,do install apollo-server and graphql
npm install apollo-server graphqlApollo Server is an open-source, spec-compliant GraphQL server that’s compatible with any GraphQL client, including Apollo Client. It’s the best way to build a production-ready, self-documenting GraphQL API that can use data from any source.
You can use Apollo Server as:
- The GraphQL server for a subgraph in a federated supergraph
- A stand-alone GraphQL server
- An add-on to your application’s existing Node.js middleware (such as Express, AWS Lambda etc…)
Add the code snippet below to the src/index.js
const { ApolloServer } = require('apollo-server'); const typeDefs = ` type Query { hello: String! } ` const resolvers = { Query: { hello: () => `Hello World` } } const server = new ApolloServer({ typeDefs, resolvers, }) server .listen() .then(({ url }) => console.log(`Server is running on ${url}`) );
typeDefs: To define your GraphQL schema. Here, it defines a simple Query type with one field called info. This field has the type String!. The exclamation mark in the type definition means that this field is required and can never be null.
Resolvers: This object is the actual implementation of the GraphQL schema. Notice how its structure is identical to the structure of the type definition inside typeDefs: Query.info.
ApolloServer: Which is imported from apollo-server.Finally, the schema and resolvers are bundled and passed to it This tells the server what API operations are accepted and how they should be resolved.
Also, you can make it as separate files like typeDefs.js and resolvers.js.
Now we have done with the basic setup. Next, we have to test the graphQL server.
node src/index.jsNow the server is now running on http://localhost:4000. When we go to this we can see a GraphQL Playground, (GraphQL IDE that lets you explore the capabilities of your API in an interactive manner.)
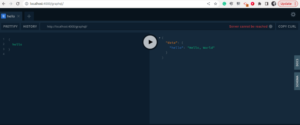
Let’s go ahead and send your very first GraphQL query. Type the following into the editor pane on the left side:
query { hello }
Now send the query to the server by clicking the Play-button in the center.
Conclusion
In this article, We have covered some basic information regarding the GraphQL and development of GraphQL with Node.js.These are some very basic things which may helpful for beginners, and I hope so.